After Meltdown and Spectre, more vulnerabilities in out-of-order CPUs have been uncovered that use similar side channels. This article is about the L1 Terminal Fault vulnerability, a meltdown-style attack that is also effective against up-to-date system software incorporating KPTI-like patches.
Last updated:
Jacek Galowicz
Founding Partner
After Meltdown (see also our article about Meltdown) and Spectre, more vulnerabilities in out-of-order CPUs have been uncovered that use similar side channels. This article is about the L1 Terminal Fault vulnerability, a meltdown-style attack that is also effective against up-to-date system software incorporating KPTI-like patches. L1 Terminal Fault actually refers to three different vulnerabilities with the ancestor being the Foreshadow vulnerability that was published at this year’s USENIX Security Symposium. While the article authors focus on SGX security aspects we are more concerned about implications for virtualization as it also enables crossing virtual machine borders with uncomfortable ease.
The original Meltdown vulnerability attacked the supervisor/user mode access permission checks. That is, an address translation had to exist in order to access a memory location. This new variant leverages a flaw in processing non-present addresses and, as a consequence, it can be used to access arbitrary physical memory locations. Of course, configuring such a physical address requires supervisor privileges, making the attack particularly attractive with a malicious operating system (OS).
Extended Page Tables (EPTs) are designed to provide extra hardware-level protection in case of virtualization. They supposedly guarantee strict isolation of Virtual Machines as their OS can configure a so called Guest Physical Address (GPA), only, that gets translated to the true physical address on the host (HPA) in a subsequent step. In this case, however, the attacker can specify an HPA directly because the EPT translation is skipped. Thus, an attacker might launch his own VM in a cloud environment and probe memory content belonging to other, co-located VMs, a task that would usually require hypervisor privileges.
Implications
A short summary of what this security bug means:
Code utilizing this exploit works on Windows, Linux, etc., as this is not a software- but a hardware issue.
It is possible to retrieve content from arbitrary physical memory locations (this comprises kernel/hypervisor/SMM memory) as long as the data is cached and the virtual address is not present in the Translation Lookaside Buffer.
This last restriction implies that full control over which physical addresses get accessed requires code that can alter the CPU’s page tables, most notably guest operating systems within a virtual machine.
Affected software:
So far all versions of all operating systems (Microsoft Windows, Linux, MacOS, BSDs, …)
All hypervisors (Microsoft HyperV, KVM, Xen, Virtualbox, …)
All container solutions (Docker, LXC, OpenVZ, …)
Code that uses secure SGX enclaves in order to protect critical data.
The earlier published KPTI/KAISER patches that protect against Meltdown provide no protection against this vulnerability.
Affected CPUs:
Intel “Core” Series, dating back to at least 2006
SGX is an Intel-only technology i.e., Foreshadow applies exclusively to Intel
Since the vulnerability is caused by the specific implementation of processing page table information it is unlikely that other CPU manufacturers are also affected
Microarchitectures used in Intel’s Atom and Xeon Phi lines are not susceptible
Sole operating system/hypervisor software patches do not suffice for complete mitigation: Some form of cache wiping mechanism needs to be added to the CPU’s instruction set.
In addition to that, SMT (Simultaneous MultiThreading, aka Hyperthreads) should be deactivated because hyperthreads share the physical core’s L1 cache. Otherwise, one logical core could void the cache wiping actions of another.
Security related consulting
If you have any questions about Meltdown/Spectre and their derivatives, their impact, or the involvement of Cyberus Technology GmbH, please contact:
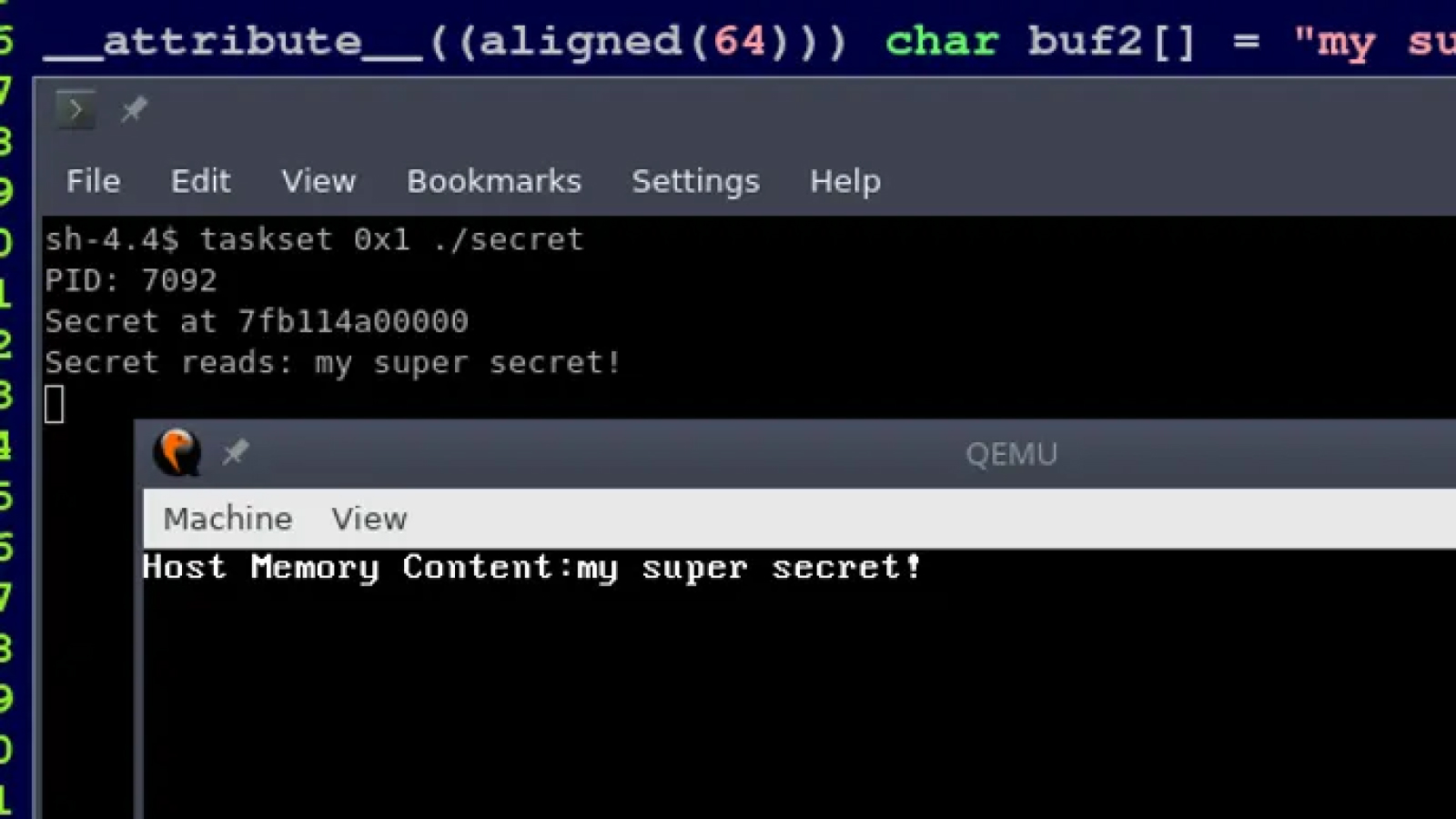
The attack vector we present here is different from the one presented by the Foreshadow paper authors, who concentrate on secure SGX enclaves. At Cyberus Technology, we had a look on this vulnerability from the perspective of virtual machine security, as we are a virtualization software products company. The Foreshadow authors also published a technical report about other L1 terminal fault vulnerabilities which complements our analysis. Within the scope of our research we were able to implement a proof-of-concept that is able to reliably dump hypervisor memory at nearly arbitrary (see L1D cache restriction) addresses from a virtual machine guest:
Attackers can create their own guest image with exploit code. Its execution allows them to read confidential data from the virtualization host’s physical memory, which, of course, includes confidential data from other customers of the same virtualization service.
Technical Background
In a nutshell: The process of utilizing this vulnerability has some similarity to the Meltdown Attack we described in our article from January. The attacker makes sure that the currently active page table contains a mapping from some virtual memory address to the desired physical address in host memory. This mapping must be marked as non-present and be flushed out of the Translation Lookaside Buffer (TLB). At the same time, the mapped-to memory must still reside in the L1 cache of the core on which the attack is deployed. Meeting these prerequisites, the attacker performs a read access to that virtual address. Since this read access is illegal, a side channel has to be used to disclose the transient microarchitectural state. For example, this could be the same selective cache line warming trick that is already known from the Meltdown attack.
The root cause is that, similar to the original Meltdown vulnerability, memory load operations are allowed to proceed although the page table information indicates an illegal access. In this case, the so-called page miss handler (PMH) that gets invoked on TLB misses simply returns the data from the final page table entry when it encounters a fault condition (≙ “page not present”). The memory value will then nonetheless be speculatively looked up in the cache with the address that was just returned from the PMH, despite the non-presence of the page. Of course, this memory load will be squashed eventually, but speculative execution continues until the fault is finally delivered. As a consequence, it is possible to read raw physical memory addresses of choice using well-known cache side channel techniques, bypassing all additional protection mechanisms like EPT.
Virtual Memory
In order to decouple software execution from the actual physical hardware, programs operate with virtual memory addresses. System-level software, like an OS or hypervisor, configures special translation structures, the so-called page tables, that are consulted by hardware when performing the actual memory access. In general, a software process can access one or multiple consecutive bytes of memory by their address, which is usually expressed with 32 bit or 64 bit wide numbers. On systems with virtual memory, every process gets its own address space. If a process reads from or writes to e.g. address 0x1234.5678, this address might not be the real address that is effectively read from or written to.
We call the addresses that processes operate on the virtual linear address and the addresses of the resulting real memory cells of the hardware the physical address. With such a mechanism, we can hide the possibly confidential memory of one process A from access by any other process B by simply not using the physical addresses used by A in B’s page table. Similarly, we can let different processes access the same memory (common system libraries for example), and limit access to reading and executing, but forbidding writes. Virtual memory is a useful abstraction for enforcing process security and saving hardware memory resources, while at the same time minimizing application complexity.
For efficiency reasons, the granularity of the translations is limited i.e., a mapping applies to a range of virtual linear addresses. The minimum granularity is called a page, which is 4 KiB in Intel Architecture. Like other parts, also the address translation modes evolved over time and in the following, for the sake of simplicity, we assume the standard 32 bit address handling dating back to the 80386 CPU.
With 32 bit it is possible to address 4 GiB of memory or roughly 1 million 4 KiB pages. That is, the system software would have to configure these 1 million translation entries whenever a new process starts executing. Most programs do not need so much memory, though, so the mapping of virtual linear addresses to physical addresses is performed with a multi-level structure. This so called page table also resides in memory and is usually outside the reach of processes. Instead of a direct look-up of the virtual linear address, one has to “walk” the levels to determine the final physical address. Please have a look at the following diagram that explains how the page tables are traversed for 0x1234.5678:
First, the address is split into 3 chunks, the first two being 10 bit wide, and the last one 12 bit wide. These 3 chunks are interpreted as offsets into 3 different structures in memory. The number corresponding to the last 12 bit chunk can range from 0 to 4095, that is it provides the offset of a byte within a page. Note that a 32 bit value comprises 4 byte, hence the 1024 possible values of a 10 bit chunk fit nicely in a 4 KiB page.
Page Directory
The first level of the page table structure is the Page Directory. Every process usually has its own page directory and on every context switch from one process to another, the page directory is also switched. This is realized by letting the special CR3 register point to the currently selected page directory in memory.
The highest 10 bit slice of our virtual linear address 0x1234.5678 have the value 0x48 when they are interpreted as a number. This value 0x48 (which is 72 in decimal) is used as an offset into the page directory, which has 1024 entries. Entries can be either not present, which means that they contain no address translation, which then in turn means that the address is not accessible for the process. Present entries, on the other hand, contain the physical address of the page table that is one hierarchy level lower, plus additional information like access rights.
Page Table
Similar to the page directory, the page table also contains 1024 entries with pointers to the next lower hierarchy level and additional information like access rights. Just as page directories, page tables can also be present or non-present.
The middle 10 bits of our virtual linear address 0x1234.5678 result in the value 0x345 (which is 837 in decimal) which is now used as the offset into the page table that the page directory entry we consulted before points to. The pointer of the page table entry at this offset is identical to the physical address of the corresponding page frame.
Page Frame
Page frames have the same size of 4096 bytes as the page directories and page tables the CPU has traversed so far, but it does not act as a lookup table. A page frame contains the actual physical memory a process finally gets to access and store data at. Within this page frame, the lowest 12 bit of the virtual linear address 0x1234.5678, the value 0x678 (decimal 1656), are the offset of the actually accessed data cell. This means that only the highest 20 bits of a virtual linear memory address are really virtual, as the lowest 12 bit are not changed after applying the mapping from virtual to physical addresses.
"It is important to say virtual linear address, because actually, processes work on virtual logical addresses that are yet to be translated to linear ones. Such translation is performed by so-called memory segments. We are omitting the explanation of this mechanism because it is not relevant to the understanding of the CPU vulnerability."
The following diagram, which is extracted directly from the Intel Software Developer Manual for the Intel x86 architecture, describes the structure of 32 bit virtual memory: The CR3 register, page directory entries (PDE), and page table entries (PTE), all with present and non-present state. The “4MB page” PDE is a special case that we do not describe further in this article, as it is again not needed for understanding the vulnerability.
Translation Lookaside Buffer (TLB)
The statement that the page table is walked by the CPU for every memory access was a lie. Traversing the whole page table would impose quite a performance penalty because of the 2 extra memory lookups necessary for every access of a virtual linear memory address. Similar to the way data caches are used to speed up standard program execution, the translation result can also be cached and the corresponding hardware structure is called Translation Lookaside Buffer (TLB). The TLB is a simpler form of lookup table that is able to store a limited amount of recent virtual-to-physical address translations.
Data Cache
Accessing main memory is significantly slower and more energy intensive than fetching data from on-chip storage cells. Hence, CPUs store a subset of the data locally in order to accelerate program execution. These caches are nothing but another look-up structure: they take a memory address as input and return the value that the system memory is supposed to hold.
If the physical address was used for the look-up, the CPU would have to perform the address translation first. Even if it was found in the TLB, this would result in sequential execution of 2 cache accesses (first the TLB, followed by the data cache). Recall that the lower 12 bit of the virtual linear address are identical to the physical address. Thus it is possible to perform the data cache look-up with the virtual address as index and consult the TLB in parallel, hence saving time.
The attentive reader might object that 2 different processes can have different mappings to the actual data and an aliasing problem arises. In order to correctly distinguish such different mappings, the cache employs a mechanism called tagging. In addition to the value, the cache also stores the corresponding physical address and before the CPU continues data processing it compares this physical address tag with the result from the TLB look-up. Such a cache is said to be virtually indexed, but physically tagged (VIPT). Please see the wikipedia article about Caching that contains further information about indexing vs. tagging.
Special Role of the L1 Cache in the Foreshadow vulnerability
Data caches exist in different flavours, ranging from a small, private first level (so-called L1 cache) to bigger, shared structures (usually called L3 cache in Intel products). The bigger the cache, the slower the access, hence it makes sense to use the physical address as index for the next levels as the TLB look-up has already been completed when a L1 miss is detected. Depending on the exact implementation of error handling while walking the page tables, the time window for looking up data may suffice for L1 access, only.
On systems with Simultaneous Multithreading/Hyperthreads there are 2 logical cores that look like real cores to software, but operate on the hardware structures of the same physical core. Among such shared hardware structures is the L1 cache. For attacks that can access physical address values that are present in the L1 cache, this has the implication that one hyperthread that might operate on behalf of one process, can access the values that are cached on behalf of the other hyperthread. These processes can even run in different virtual machines.
The Attack
We assume the following things:
The attacker has the privilege of an operating system kernel. This way it can manipulate the page tables directly.
The attacker’s code runs in a virtual machine that we call the attacker VM.
On the same host system, there is another VM, the victim VM.
The victim VM keeps some confidential data in memory.
The attacker code knows at which physical address of the host system that confidential data resides. Let’s assume it’s address X = 0x12345678
During the attack, the value of X must reside in the L1 cache of the core on which the attacker code is also running.
Now, the attacker can do the following:
First, she/he creates a page directory or page table entry that maps from some virtual linear address to the page frame that begins at 0x12345000. The entry shall also mark this entry as not present.
Next, it must be ensured that this mapping does not exist in the TLB. Such a mapping can simply be flushed in case it exists.
Next, the following sequence of assembler instructions is basically the same as in the classic meltdown attack:
; rcx = our virtual linear address to the host's physical address 0x12345678 ; rbx = address of a large array in user space mov al, byte [rcx] ; read from forbidden kernel address shl rax, 0xc ; multiply the result from the read operation with 4096 mov rbx, qword [rbx + rax] ; touch the user space array at the offset that we just calculated
The attacker puts the mapping that points to the desired host page frame into register rcx and tries to access it. When the pipeline attempts to perform the memory load from this address, it will realize that this address is not accessible from the cache, because the cache entry does not fit for the logical attacker core. Next, the TLB is consulted, but it does not contain the virtual-physical mapping. As a consequence, the memory management unit is about to walk the page table entries, but the attacker marked them as non-present, which is also called a terminal page fault.
The effective consequence of this series of happenings will be a page fault. What happens inbetween, is interesting: The whole pagefault determination and delivery takes some CPU cycles, so the pipeline attempts to perform the load operation speculatively. While doing so, it naturally consults the L1 cache first, and uses 1:1 the unmodified address from the page directory/table entry that the attacker prepared. Since the L1 cache is physically indexed, this works in the transitive time window and opens the desired side channel.
The rest of the attack is analogous to the flush-and-reload strategies in other meltdown and spectre attacks. Have a look into our existing article about Meltdown to refresh how this works.
Mitigation Techniques
As the described attack can be performed either from user space or from a rogue operating system that is a guest of any hypervisor, there are slight differences.
Lazy Page Unmapping
Whenever the OS/hypervisor unsets the “Page Present” bit, it should render the accompanying physical target address mapping ineffective. This can be done either by zeroing out the whole mapping, or by setting normally unused bits (e.g. the most significant bit(s)) of the address mapping in order to make the page table entry point to nonexisting/uncachable memory.
Cache Hygiene
In general, when switching from a critical context to the potential attacker context, at least the L1 data cache should be purged. (This goes with the assumption that the higher-level caches are too slow to react within the small side channel time window) This would be the case when switching back from kernel space to user space, or prior to VMENTRYs from the context of a hypervisor. The same applies to mainboard firmware that is executed in the SMM. In order to specifically flush the cache, (possibly upcoming) CPU support is required!
Since the L1D cache is shared among hyperthreads, the SMT mode must be disabled in order to be absolutely safe from leaking L1D state from one context to the other.




.avif)
.avif)