Maximizing Uptime: The Power of Live Migration for Seamless Software Updates
Discover how live migration technology empowers cloud services to perform seamless updates, ensuring your software stays fresh without disrupting operations. At Cyberus, we're pioneering innovative solutions like post migration to push the boundaries of high availability. Ready to optimize your infrastructure?
Last updated:
Philipp Schuster
Senior Software Engineer
Downtime of software services negatively affect customer satisfaction, operational efficiency or, in the worst case, revenue. As a result, high availability of software is a key factor to success of modern digital businesses. Countless services, such as websites, accounting software, or warehouse services, run in managed cloud infrastructure in Virtual Machines (VMs). All broadly used software hosted on servers somewhere on the internet should experience at best zero downtime. However, one wants to keep software fresh, to get security updates and feature enhancements. Ideally, updates are installed as soon as possible, without any visible delay. Here, a natural conflict arises. Updating software through live-patching is error prone, complex, and has proven to be only a temporary solution. At a certain point, one needs to restart software, which causes a pause in the execution of software. (Live) migration is a solution to that problem.
Understanding Virtual Machine Live Migration and Its Importance
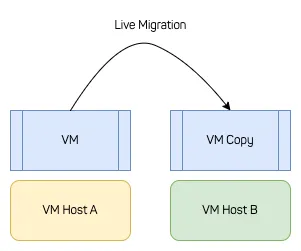
Migration is the transfer of VM state from one Virtual Machine Manager (VMM) process to another VMM process, usually across the network. The sender VM is stopped and the receiver VM started, once all state is transmitted. Ideally, neither the software running in the VM nor a user connected to the VM’s workload experience a different environment after a migration. The VM state includes device states, and memory, and stored files on persistent storage.
Live migration is a migration with (almost) no customer-visible impact, i.e., no visible downtime. So, even if the VM host changes, the actual workload keeps making progress. Depending on users and their needs, the migration downtime usually must be lower than 5ms or 100ms to be truly “live”.
A live migration does not mean that it happens instantly. For large VMs with large working sets, live migrations might take multiple hours. The relevant metric for a migration to be “live” is downtime and whether there is user impact.
Utilizing Live Migration to Minimize Downtime
First, from the introduction, we learned that high availablilty and freshness of software are two fundamental goals. Second, mechanisms for (live) migration are relevant to cloud service providers (CSPs) to perform load-balancing, hardware-maintenance, and updates of VM host software.
If software already runs with multiple instances and not all instances are about to be updated, and the software is fault-tolerant by itself, instances can just be killed and restarted. One does not need (live) migration to keep making progress and regular restarts of VMs are fine.
A Service Provider needs live migration if the following conditions are true:
the workload inside the VM has no mechanism to recover state when one instance is suddenly gone
VM host software, such as kernel/hypervisor or the VMM, must be updated
However, a Service Provider does not necessarily have knowledge about the software running in VMs or how many instances their are, so it usually just always migrates VMs if the conditions above are met.
Technical Details: Implementing Live Migration in Cyberus’ Hypervisor
For an internal demo and proof-of-concept we implemented live migration across the network for a version of our Hypervisor, that is loosely based on Cloud Hypervisor.
For simplicity of the proof-of-concept, we migrated the state of a basic set of devices and the whole memory and the vCPU state.
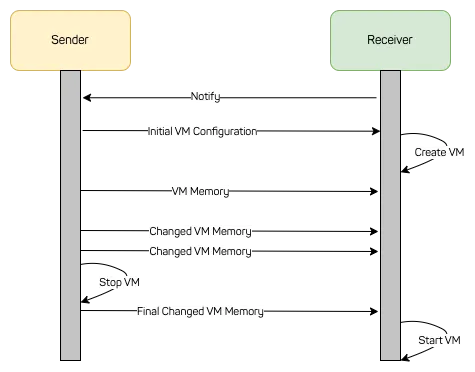
When the migration starts, the receiver side notifies the sending side that a migration is about to happen. The initial VM configuration is transmitted and a VM is built on the receiving side. The VM on the receiving side is stopped before it starts its execution, but the overall VM is properly initialized.
Next, all memory of the VM is transmitted over the network while the VM keeps running. On the sender side, the memory is directly read from guest-physical memory and put onto the wire. On the receiver side, the memory is directly put from the wire to guest-physical memory. The sender keeps making progress all the time.
However, at the moment the memory transmission starts, the sender starts tracking all writes to its VM memory. This is known as dirty page table tracking. Once the initial transmission of memory is over, dirtied pages are transmitted over the network. In that time, the sender keeps track about which memory pages are dirtied in that time.
This process is repeated multiple times. Each delta transmission takes a little less time compared to the one before, as the memory delta becomes smaller. However, depending on the workload, at a certain time the delta is not getting any smaller. At that point, the VM is stopped on the receiver side and the vCPU state and the device state is transmitted over the network. Also the final VM memory delta is transmitted. Once the receiving side received and applied all data to the VM, the VM is started and continues its workload.
Observed Results
We had a test setup where to machines were connected via a 10G link. When the working set was small, we migrated a VM between hosts so quickly that the measured downtime was less than 1.5ms. With larger working sets we completely utilized the 10G network connection and measured a 330ms downtime for a final working set of 400MB. This can be further optimized in production code, e.g. by implementing post migration, and by utilizing faster networks.
We performed hundreds of migrations without a single failure. Because of Rust, its nice abstractions and memory safety, it was an rather easy task to implement all the networking functionality. We at Cyberus love Rust, for reasons like that.
Post Migration for Further Improvements
Post migration is a slightly different approach compared to live migration which enables even smaller downtimes. When the memory delta doesn’t get any smaller on the sender side, we do not transmit the final memory delta but only the vCPU state. On the receiver side, we only mark which memory pages are missing. The VM on the receiver side starts running. Each time a page is accessed that is not there yet, it is requested over network.
Effectively, a VM is slightly less performant until all pages are transmitted with that approach, but the downtime is not effected by the final memory delta. On the receiver side, this approach is a little like loading swapped pages, but the pages were swapped to another network host.
Conclusion
Migration of virtual machines enables better maintenance of the underlying infrastructure. Systems can be patched without annoying and costly downtimes to customers and end users. However implementing migration in a way that provides value to service providers is tricky and requires careful planning and intricate know-how about virtualization technology.
For a successful live migration or post migration, one needs to transmit the memory of a VM in multiple steps while the VM on the sender side keeps running. Each delta transmission is subsequently smaller than the previous one. After some time, one reaches a point where the delta is not getting any smaller. This is the point where live or post migration takes place.
Are you missing features in your virtualization stack? Do you need help in migrating to an open-source Linux KVM based infrastructure? Cyberus can help you: Schedule a free stack assessment today and get a quote on your missing feature!





.avif)
.avif)