Thomas Prescher, Philipp Schuster, Julian Stecklina · 7 min read
Nested Virtualization Bug Hunting with Cyberus Guest Tests
In this article, we describe our discovery of undocumented behavior in KVM's nesting feature. Learn how we solved the situation in our KVM backend for VirtualBox.
Introduction
Nested virtualization allows virtual machines to create further (nested) virtual machines. As the hardware virtualization features in modern CPUs are complex, nested virtualization can have very subtle bugs. Follow along in this blog post to learn how we found the root cause of mysterious crashes of nested Windows VMs.
This was one of the major issues we fixed before we recently announced nested virtualization support in our KVM backend for VirtualBox. Feel free to try it out!
Background: Nested Virtualization
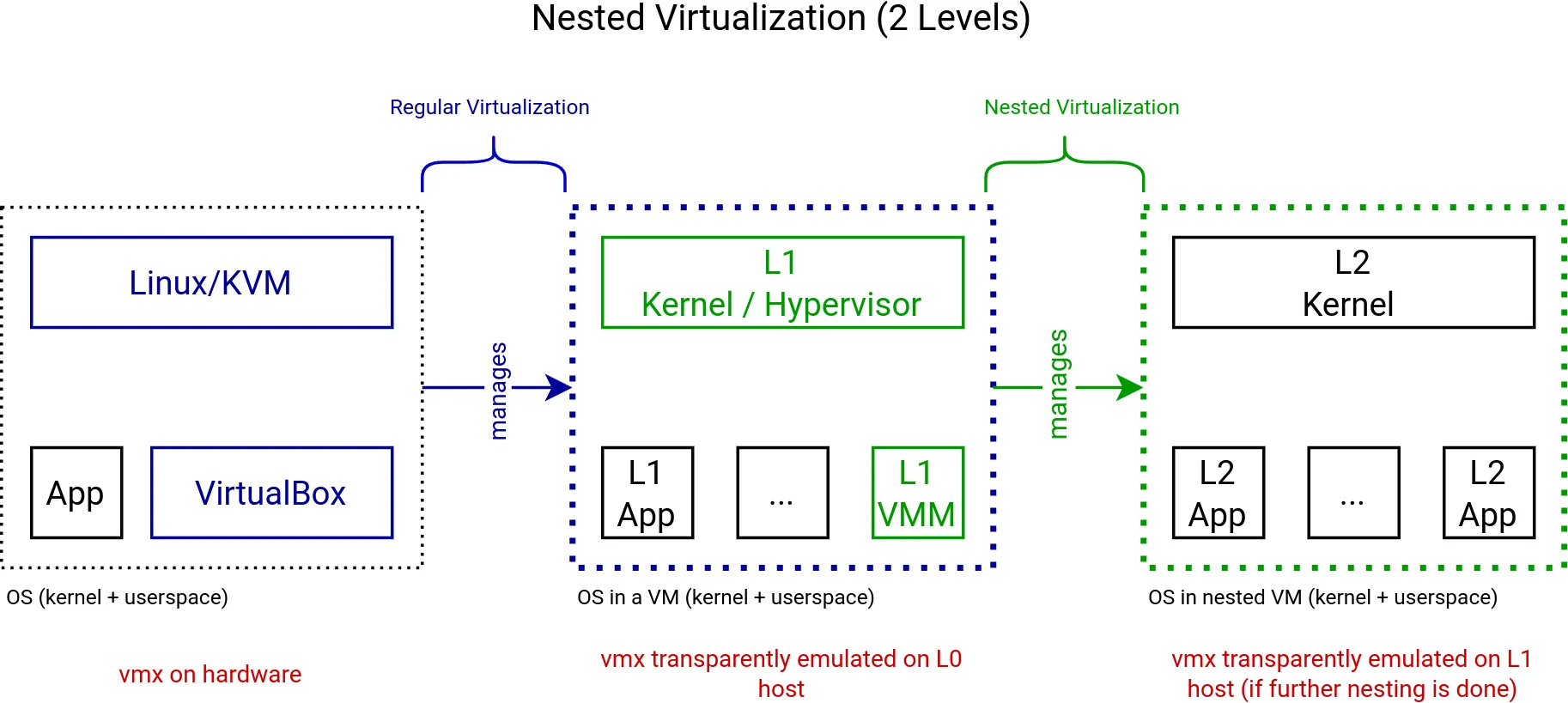
The following figure shows a nested virtualization setup with two levels. In Level 0 (L0), thus directly on the hardware, we use VirtualBox with KVM to virtualize a Level 1 (L1) guest (blue). The L1 guest then might create further Level 2 (L2) VMs, which are nested (green).
In Level 0 (L0), VMX operations run directly on the hardware. When L1 or L2 guests use VMX instructions, they are transparently emulated by the next higher level.
Technical Deep-dive and Bug Hunting
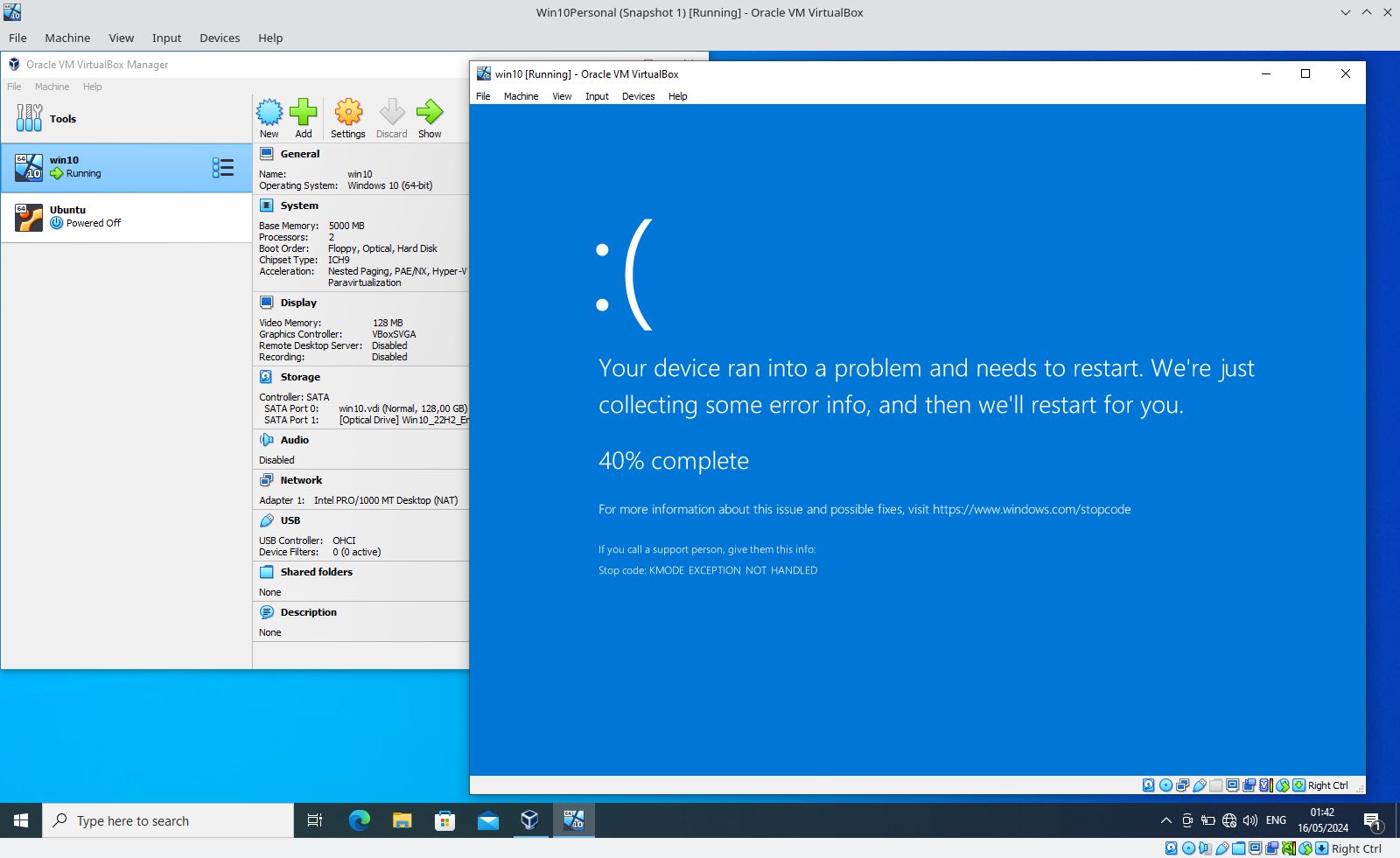
While implementing the necessary bits and pieces to use KVM’s nested virtualization capabilities in our KVM backend for VirtualBox, we ran into some interesting issues. We couldn’t explain at the time why sometimes nested Windows guests would crash during boot due to a kernel exception. These issues resulted in a lively upstream discussion on the KVM mailing list.
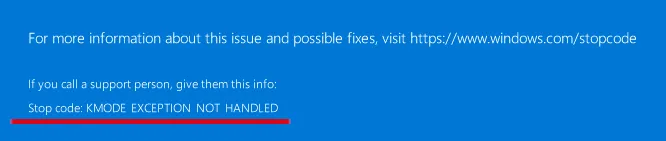
The crash didn’t happen all the time. It seemed to be related to the nested hypervisor, because we could only reproduce it in nested virtualization scenarios with our KVM backend for VirtualBox. One configuration was to run Windows in a VM, and in this Windows run VirtualBox with another Windows VM inside. The other configuration was to run HP Sure Click, which is based on uXen, inside a Windows VM. We weren’t able to reproduce it with Linux guests at all.
To narrow down the issue we dumped the code that caused the crash in the nested Windows. Unfortunately, the KVM interface provides very little control over the nested guest. For example, it’s not simply possible to intercept exceptions or read nested guest memory. So we had to hack this feature into KVM and finally extracted the following code sequence:
mov %cr4, %rax
mov %rax, %rcx
btc $7, %rax
mov %rax, %cr4 // 1) <- The crash happens here!
mov %rcx, %cr4
mov %cr3, %rax // 2)
mov %rax, %cr3This is a translation lookaside buffer (TLB) invalidation sequence. What the nested guest operating system is doing here is
- flush global TLB entries by toggling
CR4.PGE, and - invalidate non-global TLB entries by writing to
CR3.
So now we knew that the exception was happening when the guest tried to write to a control register. After checking the Intel SDM for the possible exceptions for control register writes, the only exception that made sense in this situation was a general protection fault (#GP).
Now we tried to find out whether the exception was generated by the CPU itself or whether it was injected into the nested guest by the L1 hypervisor. Using kernel event tracing to check for kvm_nested_vmexit_inject events, we could quickly identify the L1 hypervisor as source of the exception.
A Minimal Reproducer
With all the information we had now, we could isolate the scenario to have a reliable reproducer. The goal was to have complete control of the situation. And we had just the right tool to do so, the Tinivisor.
The Tinivisor is part of the Cyberus Guest Tests. It allows us to transparently switch between VMX root and VMX non-root mode while, at the same time, having complete control of the VMX hardware. So we took the code from above, and let the tinivisor execute it in a loop.
test case: test_tinivisor_cr4
[INF main.cpp:176] CR4 is: 20
[INF main.cpp:176] CR4 is: a0
[INF main.cpp:176] CR4 is: 20
[INF main.cpp:176] CR4 is: a0
...
[INF main.cpp:176] CR4 is: 20
[INF main.cpp:176] CR4 is: a0
[INF main.cpp:176] CR4 is: 20
[INF main.cpp:183] Invalid cr4: 2020
Assertion failed @ test/guest/tinivisor/main.cpp:185Now, the story gets interesting: After many boring iterations, out of the blue our guest was trying to set CR4.VMXE (0x2000). This would cause the crash in Windows, because our nested guest does not have access to VMX! Also the only way this code can set this particular bit, is when it reads a value from CR4 that it has not previously written. Because the issue doesn’t immediately happen, it has to be timing-related as well.
Signals of a Problem
The fact that the issue was timing-related quickly got us to look at the signal path. Signals are used to interrupt vCPU execution when userspace needs to get back control. And this is where things got really confusing.
Signals are primarily used for two things:
- the VMM wants to inject an interrupt into the (non-nested) guest
- the VMM wants the guest to stop executing to do work within the vCPU context
In neither of these situations the control register should be modified, especially not for the nested guest, because these signals are meant to interrupt the L1 guest.
Control register handling in VMX is rather complicated. When a guest reads a control register, there are multiple hardware registers that are used to calculate that value. As we know the guest suddenly sees CR4.VMXE, the READ_SHADOW field for CR4 is especially interesting. It holds the value the guest sees for this particular bit.
With this information, we traced all situations in the kernel where the READ_SHADOW field is updated. Luckily, there are only a handful of situations and we could identify the trouble causing one: after a VM exit caused by a signal, vmx_set_cr4 was configuring an incorrect READ_SHADOW value.
At this point, we thought this is a KVM bug, and we even thought we found the right solution to fix this issue. We came up with this (wrong) patch and submitted it to the Linux Kernel Mailing List.
Bug or Feature
In the (very productive) discussion, we learned that it is possible for the L0 VMM to exit with L2 state. This is a rather unexpected situation and something that was not obvious to us reading the KVM API. The L0 VMM typically exits with L1 state, the only way that it exits with L2 state is during a signal exit.
While knowing that we can see L2 state in L0 cleared up some of our misconceptions, it still didn’t explain why the CR4.VMXE bit was suddenly appearing. After more debugging, we found that the underlying issue was due to an inefficiency in our KVM backend for VirtualBox. There are situations in which VirtualBox marks control registers as dirty even though they haven’t changed. This is not an issue if VirtualBox handles an L1 exit, but it is an issue if the exit originates from the L2 guest.
So the situation is that, during an L2 guest, VirtualBox was marking CR4 as dirty, even though it’s state didn’t change. This caused the READ_SHADOW to be modified and leak state from the L1 guest into the L2 guest.
The mailing list discussion made clear that this is expected behavior. The workaround is to avoid marking unmodified state as dirty. This is also the solution we have picked for our KVM backend for VirtualBox. However, it is still not clear how a VMM can reliably detect a L2 exit and avoid running into the same problem as we did.
Improving the Status Quo
We submitted a new patch that allows VMMs to probe for this situation and updates the documentation. We also identified scenarios where Qemu does not handle this situation correctly either and hope that our patch will help to simplify VMM implementation.
So while our immediate crash problem is solved for now and the KVM backend for VirtualBox has stable nested virtualization, the story hasn’t really concluded yet. We plan on writing an update once we have a permanent solution that also benefits other VMMs on Linux!